Метрики BI-системы как продукта
Я считаю, что главная задача BI-системы помогать бизнесу быстро принимать решения, без рисков связанных с утечкой данных и ошибок из-за неправильных данных. Поэтому идеальной метрикой работы системы могли бы быть Time to Insight или денежная выгода от принятых решений с помощью это системы. Но я не придумал, как измерить это «по-честному» без аппроксимации в виде опросов «оцените сколько времени сэкономило вам внедрение дашборда». Кажется, что померить реальный экономический эффект от внедрения почти нереально или будет настолько затратно, что съест всю эффективность. Поэтому я выделяю группы метрик, которые, я верю, являются прокси к этим двум true north метрикам и их можно довольно просто померить. Эти группы следующие:
— Качество отчетности
— Скорость использования
— Вовлеченность
— Инфраструктура
Давайте пройдемся по каждой группе и посмотрим какие метрики можно выделить в каждой из них. Мы пришли к этим метрика не сразу, а через ряд итераций, проб и ошибок. В целом при формировании этого списка мы шли «от цели», то есть выписывали какие результаты мы видим важными, а дальше думали как мы можем это измерить. Одна из первых таких диаграмм-размышлений на картинке.
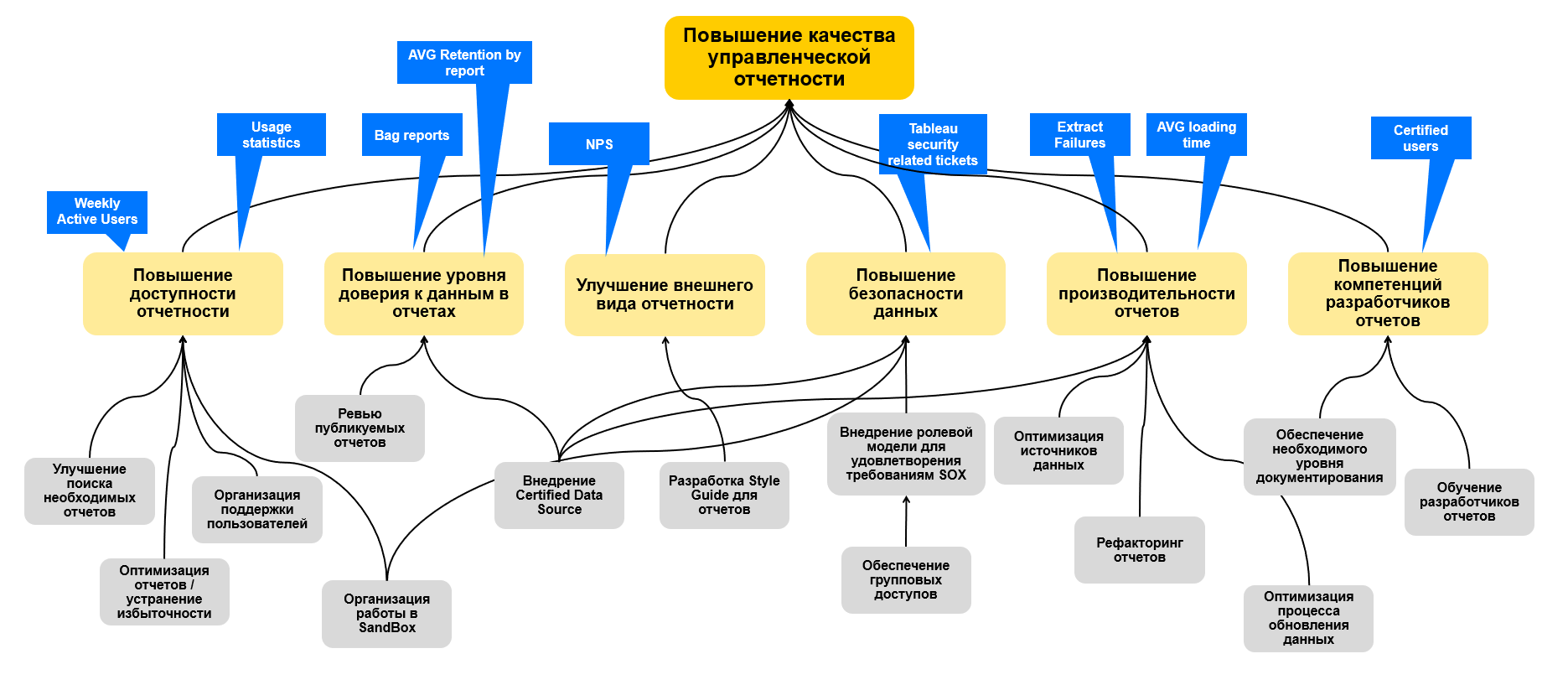
Качество отчетности
На мой взгляд это самые важные метрики, так как наиболее комплексно описывают удобство и пользу от работы с системой.
«Аля NPS»
Качество отчетности можно проверять качественно и количественно. Для качественного исследования можно использовать опросы, мы проводим такой раз в полгода и узнаем у всех пользователей насколько им удобно пользоваться нашей системой. В итоге мы не измеряем именно NPS, но смотрим за средним баллом от 1 до 10 в целом и по отдельным вопросам. Основной вопрос: «Оцени по шкале от одного до десяти отчетность, которой пользуешься в Tableau. Интересуют любая отчетность в целом, которой ты пользуешься регулярно.» И девять дополнительных: Выбери наиболее важные пункты и не ставить много одинаковых оценок. 1 — «ужасно, займитесь в первую очередь», 10 — «всё и сейчас отлично»:
— Отчеты позволяют принять нужные бизнес-решения
— В отчетах есть нужные метрики/разрезы
— Понятно как считаются KPI в отчете
— В отчетах качественные данные (полные и правильные)
— Данные обновляются своевременно
— Легко найти нужный/новый отчет
— Отчеты работают быстро
— В отчетах понятная визуализация данных
— В отчетах понятный и удобный интерфейс
Ответы на эти вопросы помогают понять общую обстановку + узнать конкретные слабые места системы. Так же есть возможность оставлять текстовые комментарии, оттуда мы получаем много полезной информации. По результатам опроса мы конечно же строим дашборд =)

Целевые значения, на мой взгляд, должны быть 8.5 баллов.
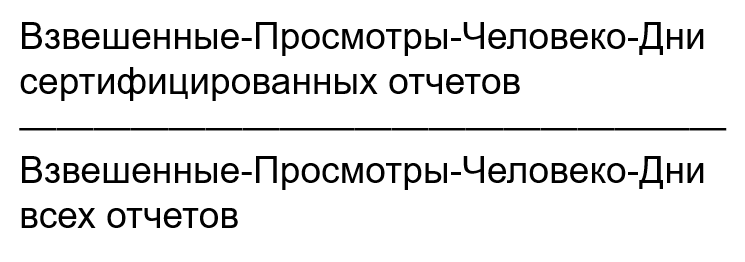
Процент просмотров сертифицированных отчетов
Следующая метрика, не менее важная, чем предыдущая и я верю, что она во многом влияет на Time to Insight — процент просмотров приходящихся на качественную отчетность. Это значит, что мы делим все отчеты на нашем сервере на «хорошие» (сертифицированные) и на «плохие» (не прошедшие сертификацию) и верим, что «хорошие» отчеты быстрее решают задачу бизнеса.
Сертификация проходит в процессе ревью отчетов, которое проходит каждый отчет который попадает в продуктовую среду. Ревью отчет предполагает проверку на формальные признаки: наличие описания и понятного названия отчета, правильность выставления доступов, использование стандартов оформления. Так и признаки, которые проверяет эксперт в своей области — удобство и UX-отчета, правильность выполнения расчетов, оптимальность написанного «кода» в Табло. По-сути данный процесс похож на ревью кода программистами, но чуть менее стандартизирован с точки зрения проверки качества работы. Если отчет проходит проверку, то он попадает в когорту «хороших» и мы сравниваем соотношение количества просмотров сертифицированных отчетов к общему количеству.
Для того что бы избежать «накручивания» метрики за счет частотного просмотра небольшого количества отчетов мы учитываем только одни просмотр человека за день, плюс взвешиваем просмотр человека на его уровень в иерархии компании, так как верим, что решения топ-менеджмента влияют на развитие компании больше, чем решения принятые на местах. То есть, условно, просмотр одного из топ-менеджером равноценен просмотрам десяти обычных сотрудников. При этом так как количество топ-менеджеров небольшое, то мы получаем баланс интересов и учтем и те, и те голоса.
В первый год нашей работы — это была наша основная метрика для управления и классно позволяла принимать решение — какие отчеты нужно улучшать в первую очередь. Я считаю, что данная метрика должна стремиться к условным 80% и не обязательно все-все отчеты должны быть сертифицированы, главное, чтобы качественными были основные, а «длинный хвост» большого количества мелких отчетов может оставаться «плохим». При этом важно только, чтобы этот хвост не мешал поиску остальных отчетов.
Данную метрику нам с командой помог придумать крутейший Женя Козлов. И у него недавно вышел классный пост, где одна из историй посвящена процессу создания этой метрики и к чему это привело. Рекомендую почитать и статью, и канал Жени.
Скорость использования системы
Второй важной компонентой является скорость работы с отчетами. При этом это не только непосредственно скорость работы в самом отчете, но и время поиска этих отчетов, получения к ним доступа и понимания как качественно работать с системой. Поэтому здесь я выделяю следующие метрики:
Простота получения доступов
Работа с отчетностью начинается еще до того, как сотрудник впервые открыл дашборд, когда он получает к нему доступы. Если в этом процессе есть много согласующих, которые долго тянут с «оком», то время на получение инсайта увеличивается. В идеальном мире человеку должны быть доступны все данные, которые ему могут быть полезны и это не нарушает политику безопасности компании. То есть человек при выходе на работу или появлении нового отчета должен быть включен в нужные группы сотрудников, которые уже согласованы. Но так происходит не всегда и часто приходится утверждать доступы.
Мы измеряем простоту получения доступа количеством индивидуальных ролей, которые пришлось получить человеку для доступа к отчету. То есть метрика — среднее количество персональных ролей для доступов на одного сотрудника. Если видим, что это число растёт — создаем новые группы и проводим обучение для аналитиков как правильно давать групповые доступы для сотрудников и создавать новые группы. Целевое значение для этой метрики нам ещё предстоит определить, но пока ориентируемся на не больше чем 5 персональных ролей на человека.
Качество онбординга
Если человек знает как пользоваться системой, где и как искать отчеты, то он будет быстрее получать инсайты. Мы приглашаем пройти онлайн обучение всех сотрудников, получивших доступ к отчетности. Далее измеряем количество прошедших обучение, доходимость и правильность ответов на контрольные вопросы. Как цель здесь можно ориентироваться, на мой взгляд, на доходимость курса порядка 60% от всех приглашений на курс.
Скорость работы отчетов
Это самая очевидная вещь с которой, к сожалению, есть проблемы в большинстве BI-систем. Скорость отклика и загрузки дашбордов зависит от большого количества переменных: от скорость работы баз данных и качества «кода» дашборда, до количества людей на сервере в моменте и действий пользователя. Мы измеряем скорость первичной загрузки отчетов и ставим себе цель, чтобы 80% отчетов на сервере открывались за 5 и менее секунд.
Вовлеченность
Чтобы от отчетов была польза, надо чтобы им пользовались (спасибо, кэп!). Поэтому важными метриками являются так же метрики вовлечения сотрудников в работу с ними.
% пользователей системы от общего количества сотрудников компании
Это метрика косвенно показывает насколько развита data driven культура внутри компании и очень важна на первых этапах внедрения и особенно при внедрении self-service подходов. Целевое значение метрики может варьироваться от отрасли компании, но, кажется, что для современной компании из IT сектора данный показатель должен составлять 60-80% от компании.
MAU/DAU
Ежемесячная и ежедневная аудитория позволяют отследить нагрузку на сервер и понимать скорость роста продукта. Здесь важны скорее не абсолюты, но темпы прироста. Целевых значений для этой метрики я бы не ставил и использовал бы её справочно.
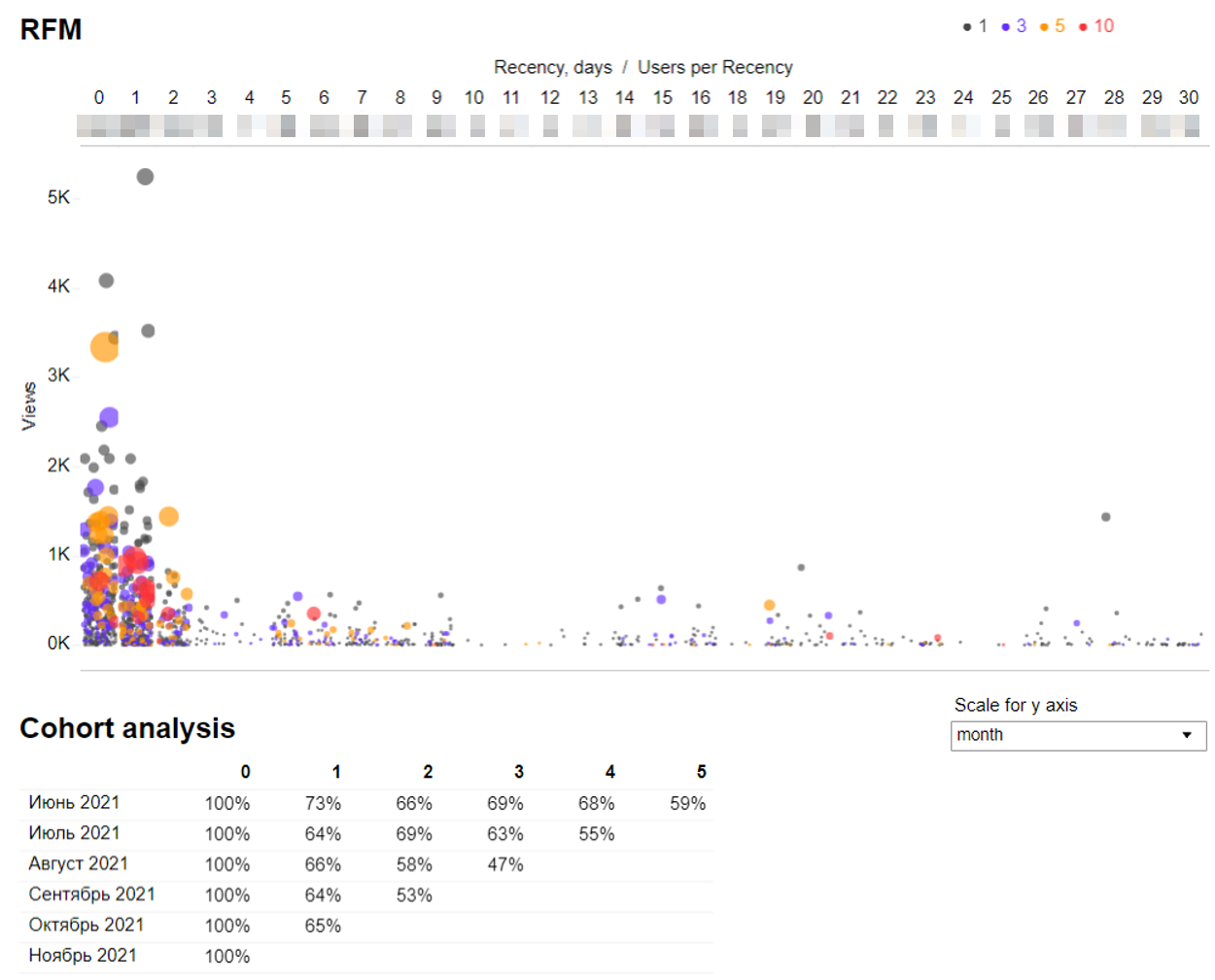
RFM
Мы стараемся применять классические продуктовые методы анализа и для внутренних инструментов. Поэтому используем и анализ вида Recency, Frequency, Monetary. Где за частоту использования берём количество просмотров, за «недавнось» количество дней с последнего захода на сервер, а вот за количество принесённых денег принимаем «топовость» пользователя в системе, то есть количество сотрудников между руководителем компании и самим сотрудником. Чем выше уровень человека, тем в большей степени его решения влияют на судьбу компании, поэтому мы перемножаем частоту заходов на коэффициент соответствующий уровню человека. Условно топ — 10, топ-1 — 5, топ-2 — 3 и т. п. Также смотрим и за когортами пользователей. Здесь нет каких-то целевых значений, зато есть проявляются паттерны и зная ретеншен по когортам, можно планировать закупку лицензий и т. п.
Инфраструктура
Последняя часть за которой мы следим с помощью метрик — это технические метрики качества работы системы.
Доступность
Это классическая метрика для любых систем. Здесь мы измеряем uptime системы и стараемся держать его на уровне 99%.
Процент ошибок
В зависимости от технических особенностей BI-системы можно следить за ошбиками в логах сервера или в обновлении данных. Мы следим за процентом неудавшихся обновлений экстрактов источников данных и количеством критических ошибок в логах сервера.
Загрузка мощностей
Здесь ничего волшебного — следим за загрузкой CPU и RAM сервера. Мы отслеживаем это в Графане, так как она позволяет смотреть за этим в реальном времени.
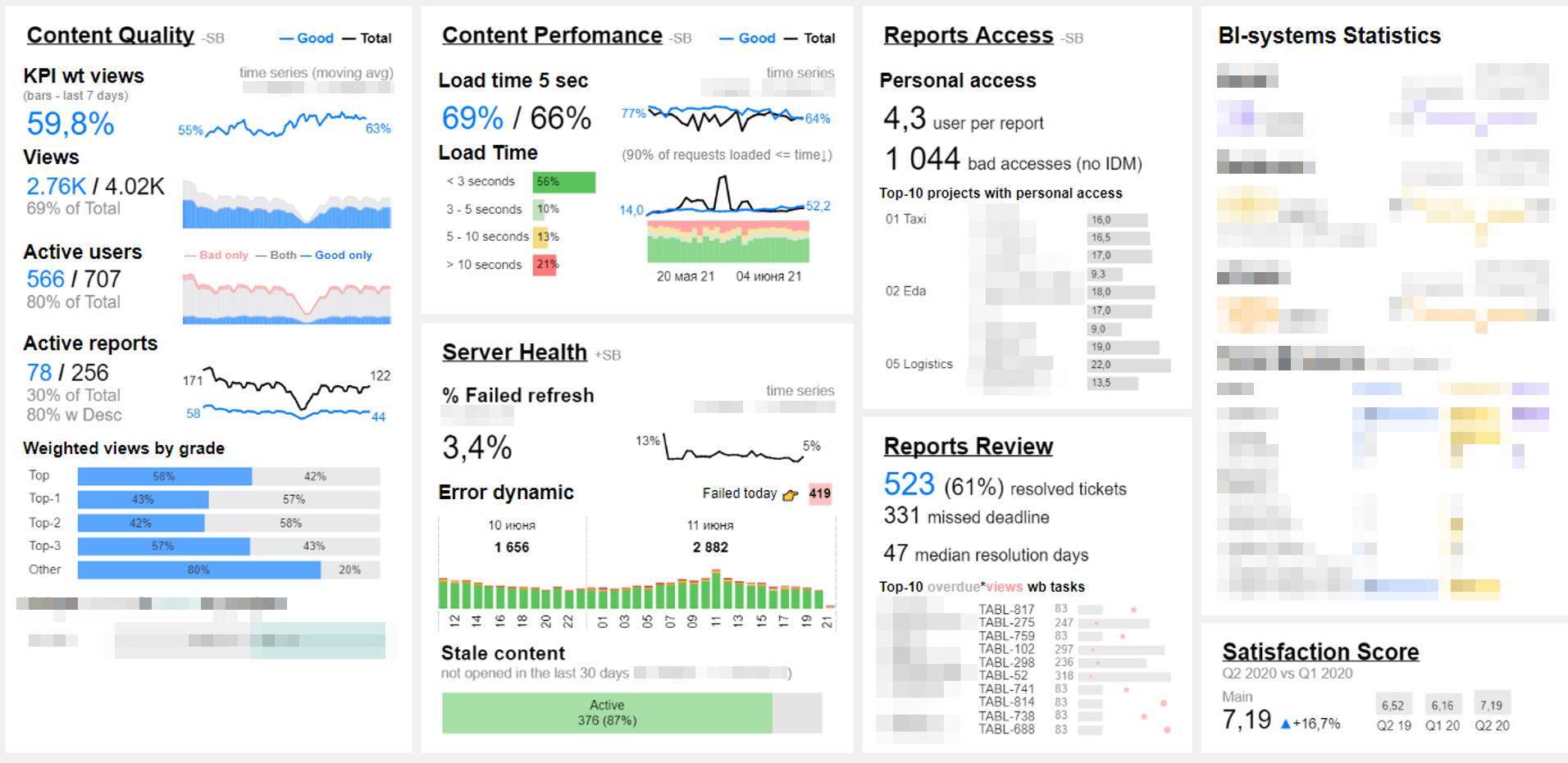
Пример дашборда
За частью из этих метрик мы следим с помощью дашборда на ежедневной основе.
Основные блоки посвящены всем разделам: качеству, скорости, вовлеченности и технической части.
Итого
Описанные метрики составляют экосистему, которая помогает нам принимать решения о том, что сейчас стоит улучшить в продукте и мы верим, что она подходит для решения наших задач. Но, например, так как у нас нет развитого self-service на стороне бизнес-пользователей, то мы, например, не следим за метриками активности создания дашбордов и т. п. Поэтому как и говорил в начале статьи — каждый кейс требует проработки системы метрик под свои задачи. Если хотите посмотреть какие ещё метрики бывают для BI систем, загляните в раздел «9. Эффективность» на доске про стратегию от Саши Баракова.