Саша Бараков недавно написал отличную статью про то, как он видит будущее развитие BI-систем. Мы с ним немного подискутировали в личке, и я тоже хочу побыть диванным футурологом и рассказать своё видение. А ещё в целом немного похоливарить про BI, у меня есть не очень популярное мнение на этот счёт.
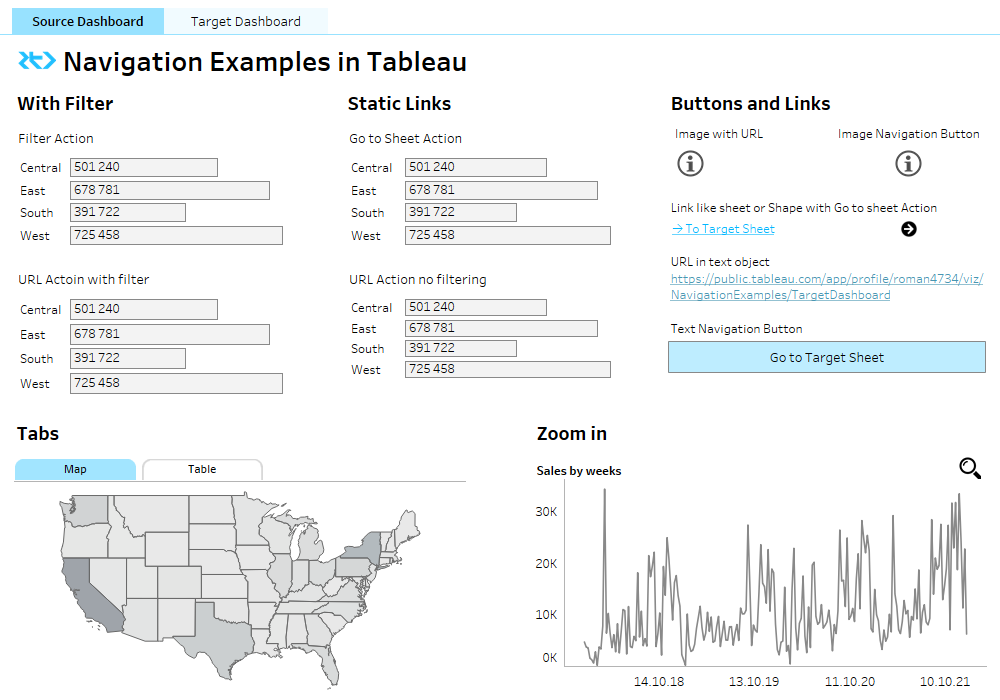
не ищем связи картинки и текста, ее нет
Что в статье у Саши
Точно стоит прочитать её полностью для формирования своего мнения, она очень классная и заставляет думать. Ниже моё субъективное восприятие:
Текущий подход к дашбордам и BI-инструментам плохо решает задачи бизнеса и вера в них слабеет. Дашбордов делается всё больше, а реальную пользу они приносят не всегда. Аналитики любят свои дашборды и переоценивают их пользу, но боятся признаться в этом. А лучше признаться позже, чем никогда. Поэтому в будущем мы откажемся от повсеместного создания дашбордов и будем управлять метаданными данных и отчетов, чтобы «умные» BI-системы с помощью AI и NLP/NLG генерировали инсайты, готовые визы и подсказки пользователям. А пользователи же собирали из этих блоков как конструктор пинборды для своих задач (не очепятка, от слова pin). При этом BI-отделы будут собирать «подборки» самых полезных пинбордов для разных ролей сотрудников, заниматься мастер-данными и иногда делать сложные отчеты.
В целом всё примерно так, но я вижу две проблемы, которые не охватывает данный подход, хочу их обсудить.
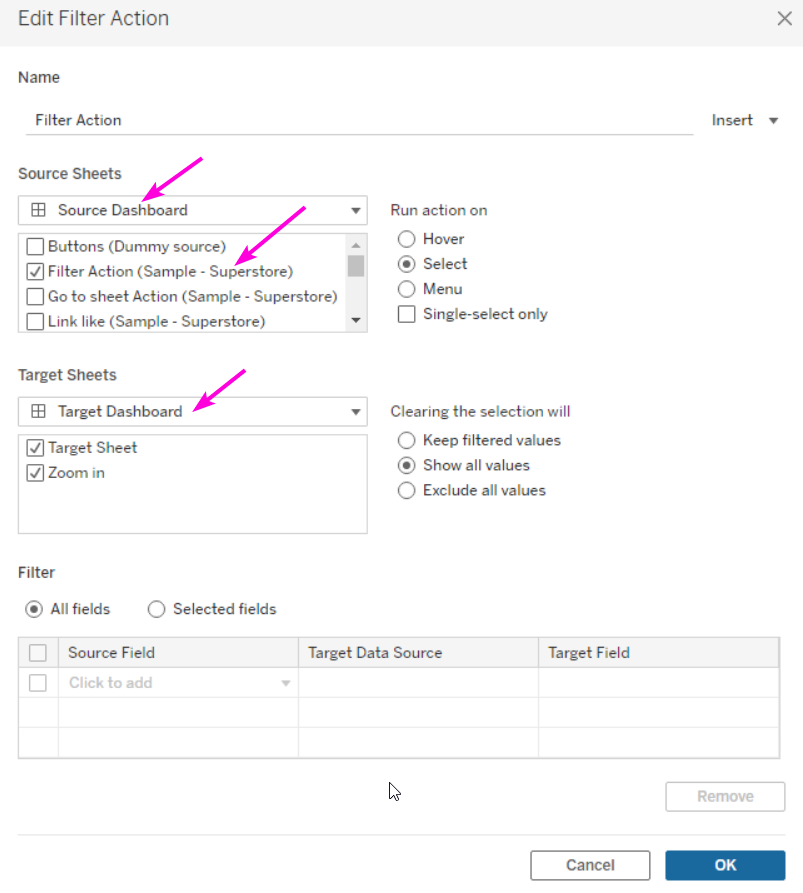
тут тоже нет связи с текстом)
Один инструмент для всех задач
Почему дашборды стали воспринимать аналитическими инструментами я не знаю, на мой взгляд это одна из основополагающих проблем отношения к ним. Почему-то операционные дашборды для управления бизнесом путают с аналитическими инструментами поиска новых знаний, а также формирования и проверки гипотез. Рассмотрим классическую аналогию. Приборная панель автомобиля говорит вам «что сейчас происходит», но не говорит куда ехать. Вы можете встроить в машину 20 спидометров, но они всё равно не подскажут направление. Итого смешиваются две задачи — операционная аналитика (хочу знать с какой скоростью еду) и поисковая аналитика инсайтов (куда и как ехать). То есть ожидания от дашбордов завышены — спидометр позволяет не схватить штраф или не вылететь на повороте, но путь вам он не укажет.
При этом и вендоры, и руководители BI-отделов, осознанно или нет, играют в «сколько денег компания заработает/сэкономит на том, что сотрудники увидят в дашборде новые идеи». Но на самом деле деньги экономятся на автоматизации создания отчётов и сокращении времени реагирования на проблемы и реже на инсайтах и новых идеях. Поэтому я считаю, что часто от BI-систем есть завышенные ожидания и в итоге разочарование, когда они не совпадают с реальностью.
Окей, во многом это вопрос терминологии. Проблема в том, что под Business Intelligence понимают разные вещи. Если посмотреть википедию, то это целый набор систем и действий от репортинга (как раз дашборды) до предиктивной аналитики и циклов улучшения процессов. Так же себя стараются позиционировать и вендоры — «мы не просто дашбордики, мы экономим вам деньги».
Но при этом большинство людей, которые слышат термин Business Intelligence, в первую очередь, думают именно о дашбордах:
Получается конфликт — изначально закладывалось, что это будет чуть ли не философия работы бизнеса, а все понимают под этим отчеты и дашборды.
Поэтому я считаю, что стоит отпустить «философскую» часть BI и сконцентрироваться на отчетности. Не стоит сваливать всё в одну кучу. Для поисковой аналитики использовать свои инструменты, для операционной — свои, и отказаться от ожиданий, что BI-система закроет задачи поиска и проверки гипотез, повсеместного генерирования инсайтов и т. п. В общем швейцарский нож нужен в экстренных случаях, в нормальной жизни эффективнее пользоваться отдельными инструментами.
Современные BI-системы неплохо справляются с операционной аналитикой, но не идеально. При этом вендоры усердно идут именно в область поисковой аналитики и пытаются демократизировать данные с помощью модных AI и NLP и т. п. Мне жe кажется, что им бы стоило в первую очередь заниматься скоростью и стабильностью работы отчетов, сквозной провязкой данных, упрощением поиска отчетности, удобством администрирования и доступа к этим системам, а не «модными» направлениям. По сути, медленно работающий дашборд (частая, к сожалению, история всех BI-систем) — это нарушение минимально необходимых ожиданий пользователя по модели Кано, но этим занимаются далеко не в первую очередь.
Поэтому я верю, что в компании должен быть хороший дашбординг/репортинг/отчетность, называйте как хотите, в подходящем для этого инструменте. А BI-отдел должен заниматься им как продуктом и платформой. Для поисковых же задач отдельно развивать аналитические инструменты и процессы работы с гипотезами. И отвечать за это уже должен руководитель аналитики данных, а не BI.
И давайте, пожалуйста, не стесняться говорить, что мы делаем Reporting. В последнее время слышу от коллег, что как будто что-то нехорошее делаю. Стоп-репортинг-шейминг! =) А то такое ощущение, что надо делать везде только Self-Service и повсеместно развивать Data Literacy. Давайте, кстати, их тоже обсудим.
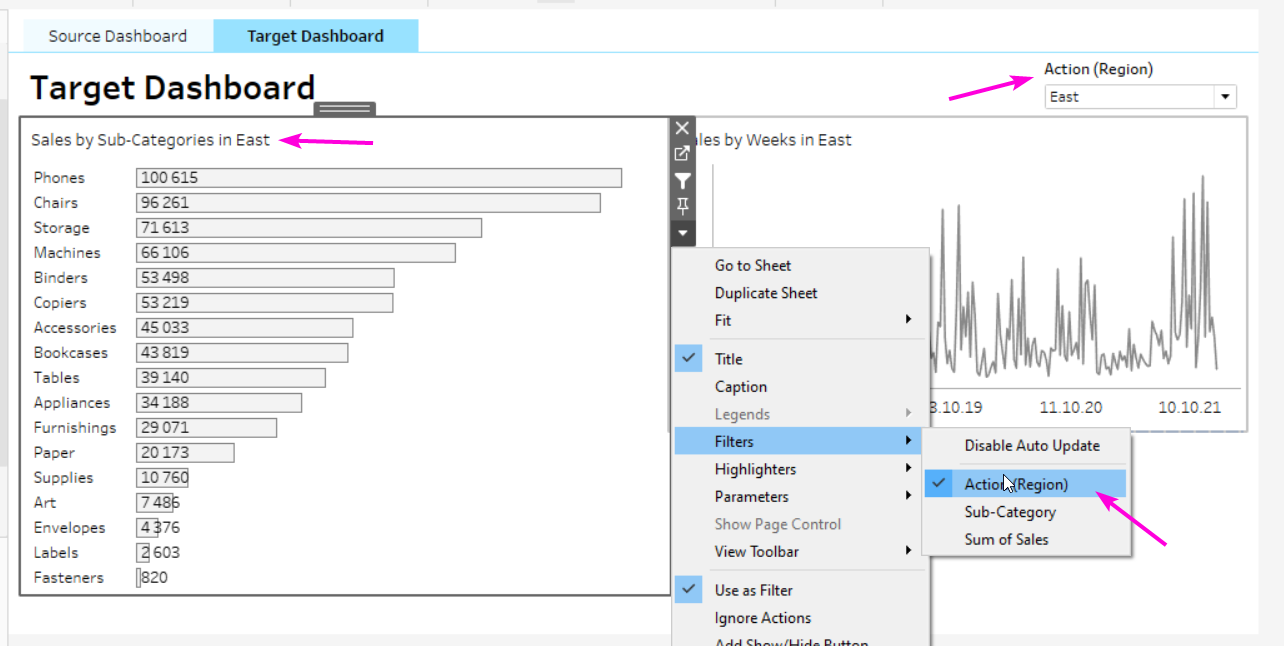
тут тоже нет связи с текстом, ну почти нет =)
Повсеместный Self-Service и Data Literacy
Сейчас говорят, что Excel — это плохо и ужасно, давайте сделаем везде Self-Service (я говорю про доступ к данным операционным менеджерам и сотрудникам, а не аналитикам в подразделении бизнеса). При этом, если Self-Service не взлетает, то впадают в две крайности: или ругают инструменты и пытаются сделать их проще с помощью NLP, Ask Data, AI и т. п.; или уходят в сторону людей — это не инструмент плохой, это пользователи не умеют работать с данными, давайте всех обучим Data Literacy.
Я уверен, что и тот, и тот путь приводят к одному — вендоры продают все больше лицензий и новых инструментов (думаю отчасти эта тема поэтому так и двигается), а люди так же плохо работают с данными и скоро будут ругать уже не Эксель и Кубы, а Табло и PBI. Так как суть будет та же — это просто прямой доступ к данным на стороне бизнес-пользователя, такой же, как был в Экеселе, который, о боже, тоже умеет подключаться к базам данных и OLAP. Проблема не в инструменте, а в управлении генерируемым контентом и решениями, которые делают пользователи на основе этих данных. Окей, тогда виноват не инструмент, давайте всех обучим работать с данными. И тут возникает вопрос: а почему это должно помочь?
Кажется, что мы, в целом, переоцениваем Data Driven подходы (здесь имеется ввиду анализ данных для принятия решения, построение гипотез и их проверка). Данные важны, но, к сожалению или к счастью, они не дают +100500% к эффективности просто своим наличием. Ты смотришь на данные и видишь, что есть проблема, но часто или не можешь повлиять на метрику, или, чтобы на неё повлиять, надо менять процессы и людей, а это супер сложно и часто понятно, что делать и без дашборда. Приведу личный пример — я собираю много данных о себе: и вес, и шаги, и сколько сижу за компом. Казалось бы: класс, наверное можно взять и получить кучу инсайтов! Но, как говорится «фигвам». Я столько раз крутил эти данные, делал красивые визы, но, по сути, это всё превращалось только в fun facts. Реальных инсайтов получить из них я не смог, а вот наличие контроля часто напоминает, что нужно что-то делать. А вот что нужно делать для улучшения здоровья, понятно и без дашборда, кеп. =)) Кажется, что так и в бизнесе, иногда надо просто взять и сделать, а не ждать красивого отчета.
Поэтому я считаю, что Data-Driven подходы должны работать не на всех уровнях компании, а только в нужных местах — на нужном уровне управления и там, где данные хотя бы в теории могут содержать инсайты и быструю выгоду. Плюс, в реальности, даже самые «цифровые компании» принимают и будут принимать многие решения далеко не только на основе данных. И чем более эти решения стратежные, тем меньше структурированных данных используется при принятии. Получается, что обучая всех сотрудников работе с данными в компании, компания не начнёт волшебным образом зарабатывать больше. Раздавая доступ к данным, нужно ещё параллельно строить процессы и культуру изменения на местах. Такими вещами занимаются методологии PDCA, DMAIC, бережливое производство и другие методики повышения эффективности. Но это совсем другие процессы и сроки, чем просто научить пользователя новому BI-инструменту или чем среднее отличается от медианы.
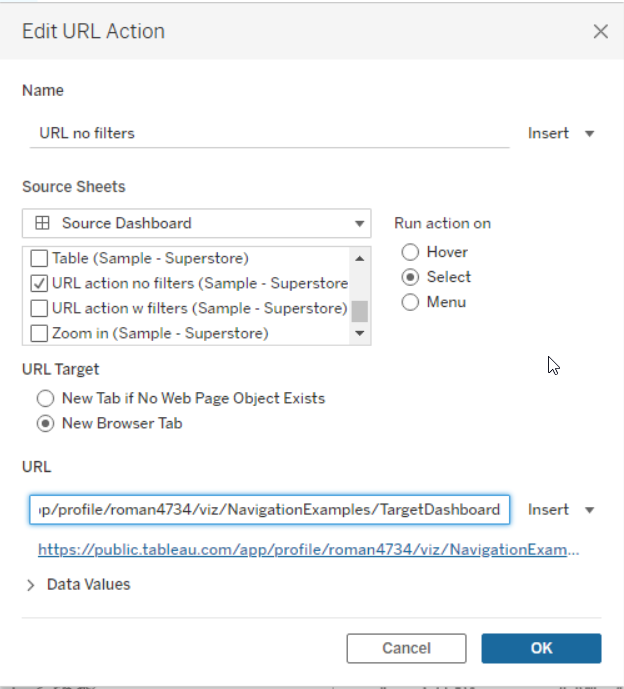
тут нигде нет связи с текстом
Что дальше
Окей, и что же будет дальше, спросите меня вы. Я думаю, что будет примерно так:
— В компаниях всё больше будут появляться BI-отделы или BI-аналитики как отдельная профессия. При этом лучше всего будут работать команды, где есть отдельный центр компетенций, а BI-аналитики привязаны к командам бизнеса. Все успокоятся и поймут, что дашборды — это просто удобный инструмент управления, но не панацея, перестанут делать дашборды на каждый чих и будут применять принцип: «лучший дашборд — это дашборд, который не пришлось делать». Критично важным станет дизайн набора дашбордов как системы и умение классно проектировать отдельные дашборды.
— Дашборды перестанут быть «диковинкой», а станут такой же привычной вещью как презентации, которые сейчас умеет готовить каждый. При этом разница между плохим дашбордом и хорошим будет оставаться как и сейчас между презентациями. Крутые специалисты будут делать хорошо, но большинство будут делать плохо, хотя и будут это уметь. Data Literacy даст буст созданию количества отчетов, но не качества.
— Хайп Self-Service пройдёт и большинство компаний разочаруются в нём. При этом появятся удобные NoCode и NLP инструменты, которые снимут часть работы с аналитиков данных, когда их используют в качестве переводчика с «человеческого на SQL-ный» для выгрузок и презентаций. Со временем это будет превращаться в свалку дашбордов, запросов и рабочих книг, но кто-то придумает крутой полуавтоматический процесс чистки таких завалов. Это упростит и ускорит работу бизнеса, но глобально не позволит сэкономить огромное количество денег, только сократит время на получение данных. При этом аналитики данных станут заниматься более важной работой по построению гипотез и изменениям продукта и процессов. Грань между аналитиками данных, продуктовыми аналитиками, бизнес-аналитиками процессов и менеджерами продукта будет стираться.
— Вокруг BI-инструментов будут появляться «над-системы», которые будут позволять бесшовно собирать в одном месте все дашборды и данные из разных систем, и в этих порталах будут создаваться аналитические рабочие места сотрудников по принципу «одного окна». В лидеры выйдут те BI-вендоры, которые буду делить инструменты по задачам и сделают рывок в базовых потребностях от системы отчетности.
— Эксель не умрёт =)
Вух, режим футуролога выключен. =) Очень хочу взглянуть на эту статью через пару лет, скорее всего ошибусь и десять раз поменяю своё мнение, но в данный момент лично я вижу всё именно так. При этом скорее это крик души, чем скрупулёзное и выверенное исследование, будьте осторожны. =)
The Dashboard is dead. Long live the Dashboard!
Связи правда нет, я просто подрезал идею у Саши в статье и захотел его немного потроллить =)
Модель — длиннопёс Юччи, фотограф —
Валерия Бунина